
When viewing a map or working with geospatial data, it is generally assumed to be accurate. But this may not always be the case, and many factors can affect accuracy. Unaccounted bias may be present, data may have been digitized at a coarser scale than was required, errors present on a previous dataset used to update a new one could be carried over, etc. So how accurate is a map or geospatial data?
Since 1998, the National Standard for Spatial Data Accuracy (NSSDA) is the Federal Geographic Data Committee (FGDC) metric used for estimating the positional accuracy of points in the horizontal or vertical direction of geospatial data. Testing uses well-defined locations to compare observed or sample data to reference or true data. Reference data might be a higher accuracy dataset, such as data at a larger scale (1:24000 versus 1:250000). It may constitute high resolution digital imagery or field survey data.
The NSSDA methodology calculates the positional error using the coordinates of the reference or true points and the observed points of the dataset being tested. The positional error, or error difference, is simply the distance between the true coordinates and dataset coordinates. It uses the equation
√(xt-xd)2 + (yt-yd)2 where xt and yt are the true point / reference point coordinates and xd and yd are the sample point coordinate locations. The resulting error distance value is squared so that there are no negative numbers (no direction to the error).
The error distances for all sample points are summed. That total is averaged for the mean square error. Taking the square root of the mean square error determines the Root Mean Square Error (RMSE) statistic for the data set. The RMSE is then converted using a multiplication factor of 1.7308 for horizontal accuracy and 1.9600 for vertical accuracy. This results in the 95th percentile in map units. The confidence level means that 95% of the positions in the dataset will have an error equal to or lower than the reported accuracy value with regards to true ground position.

Positional Error
The second lab for Special Topics in GIS partially returns me to my previous life is a cartographer and map researcher. The subject of the lab is positional accuracy of road networks, and the data provided covers a portion of Albuquerque, New Mexico. One of the projects I worked on at Universal Map was an update for the Albuquerque wall map. Back then we routinely worked with TeleAtlas data, which at the time was a substantial improvement from TIGER data, but far below today’s accuracy standards.
The lab works with two feature classes for the study area: a feature class of road centerlines compiled by the city of Albuquerque and streets data from StreetMap USA, a TeleAtlas product. 6″ ortho images from 2006 covering the study area represent the reference data.
The second protocol of NDSSA is to collect test points from the data set to which the accuracy needs to be determined. For this we implement the Stratified Random Sampling Design, which while not always possible with some data, is the ideal approach:
- Data points should not be within a distance of one tenth the length of the diagonal of the study area.
- Partitioning the study area into four quadrants, each quadrant should have at least 20% of the sampling points.

Six per quadrant, the sampling of 24 test points for the Albuquerque study area
Within ArcGIS Pro I created a layout of the study area and added guides across the center horizontally and vertically. Points were selected based upon suitability of the ortho imagery, i.e. the reference data. The principle is similar to selecting control points for georeferencing, which ideally uses geometrically linear features such as T-intersections.
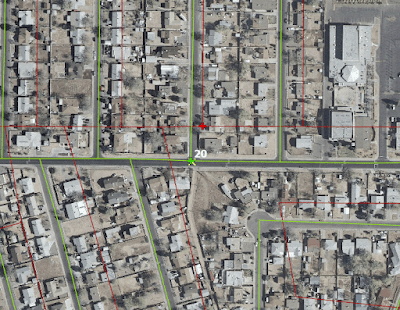
Using a T-intersection as the reference data for sample point #20
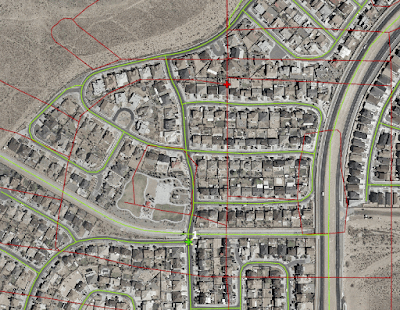
Large error distance for StreetMap USA sample point #1
With mutual ID numbers, sample points were digitized for both street centerline datasets in new feature classes. A point with a similarly corresponding ID number was digitized in a new reference feature class. Coordinate data for all points was generated using the Add XY Coordinates geoprocessing tool.

Horizontal Accuracy Assessment for StreetMap USA data
The calculations result in the error distance squared as compiled in the last column. These values are summed and then averaged. The RMSE is the square root of the mean square error, which multiplied by 1.7308 outputs the NSSDA horizontal accuracy.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}