
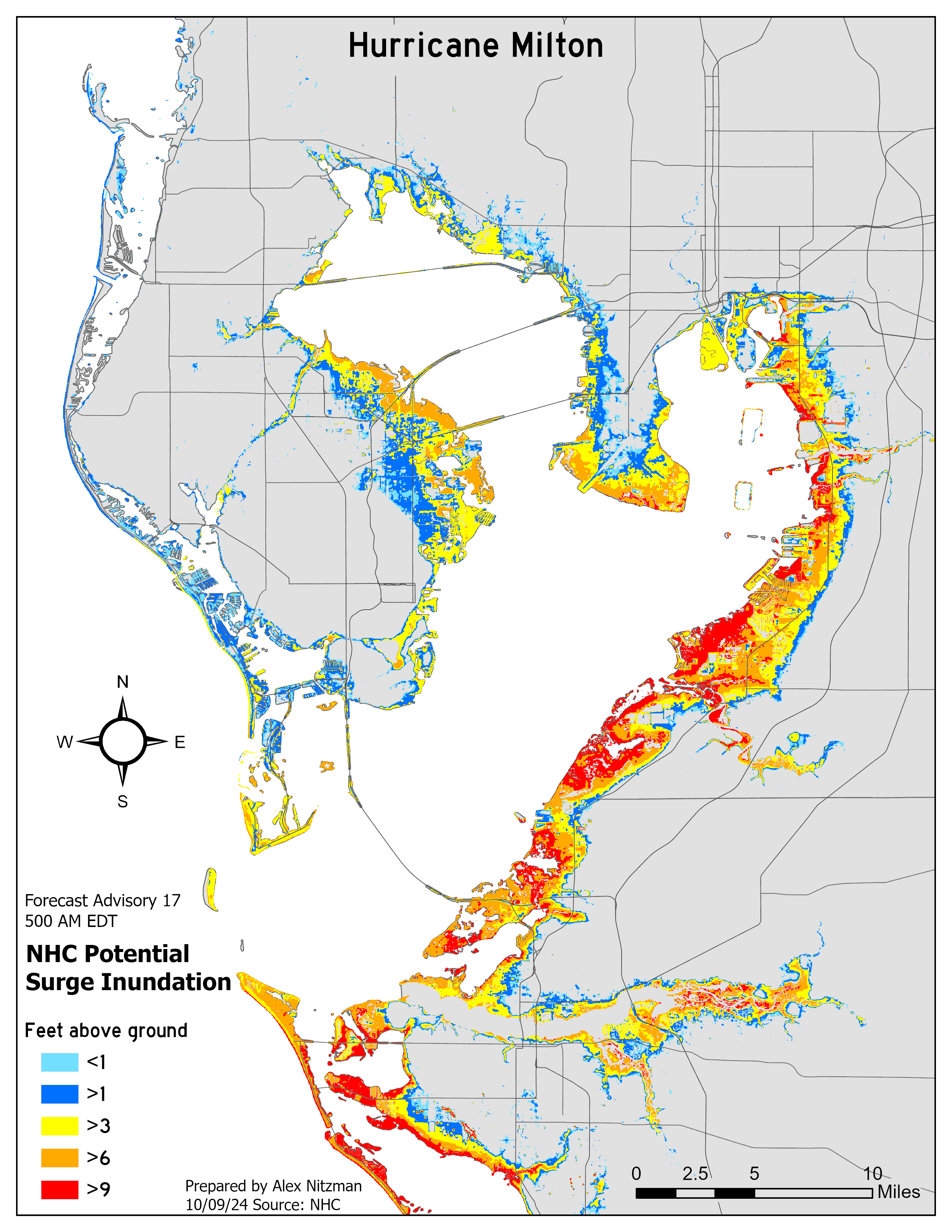
The first module of Special Topics in GIScience covers aspects of spatial data quality. Furthermore, the associated lab defines and contrasts the concepts of accuracy and precision in spatial data.
Quality generally represents a lack of error, where error in spatial data is the difference between a true value and an observed or predicted value. Rather than unrealistically attempting to know the exact error, an estimated error based upon sampling or another statistical approach or model can be used to ascertain this.
The lab for module 1 includes a point feature class of 50 waypoints collected with a Garmin GPSMAP 76 unit. We are first tasked with determining the precision of the waypoints. Precision is formally defined as a measure of the repeatability of a process. It is usually described in terms of how dispersed a set of repeat measurements are from the average measurement.
Precision is the variance of measurement to gauge how close data observations or collected data points are when taken for a particular phenomenon. If the same information is recorded multiple times, how close are these together? Tightly packed results correlate to a high level of precision.
When shooting multiple points of the same object with a GPS unit, the coordinates should be consistent, if not identical. If internal calibrations are off, obstructions exist between the unit and open sky, or a simple user error take place, the recorded points could vary widely. This would equate to low precision.
Accuracy is a measure of error, or a difference between a true value and a represented value. Accuracy is the inverse of error, and perfect accuracy means no error at all. Expressing accuracy in simpler terms, it is the difference between the recorded location of an observation and the true point or reference location of said phenomena.
How close is the recorded data from the actual location of the data? Inaccuracies can be reported using many methods, such as by a mean value, frequency distribution or a threshold value. Positional accuracy can be measured in x,y, and z dimensions or any combination thereof. It is common to use metrics for horizontal spatial accuracy in two dimensions.
If data is numeric, such as the GPS points for Lab 1, the accuracy error can be expressed using a metric like the root mean square error (RMSE). Precision, on the other hand, is commonly measured using standard deviation or some other measure. The difference between the two is that accuracy is compared to a reference or true value while precision utilizes the average value derived from data collected.

Measuring accuracy for the GPS waypoints from the true point and precision from the average waypoint based upon the mean coordinates
Using the 68th percentile, the horizontal precision was 5.62 meters. The horizontal precision was 6.01 meters. The average waypoint was 1.13 meters off the recorded true waypoint.
There are additional aspects of accuracy to consider. Temporal accuracy means how accurate data is in terms of temporal representation. This is also referred to as currentness, meaning up to date. There are also scenarios where instead of using up to date information, historical records are more appropriate.
Thematic accuracy, or attribute accuracy, relates as to whether data contains the correct information to describe the properties of the specific data element. Misclassified data is an example of thematic inaccuracy.
There are scenarios where data can be precise but inaccurate, or imprecise but accurate. If the average of all collected or observed points falls within an acceptable threshold from the true point location, this data can be considered accurate, even if the point locations are widely place, and therefore imprecise.
Conversely if a number of points are well clustered, but well away from the true point location, this data is considered precise but also inaccurate. This is also referred to as bias, which refers to a systematic error.
The second part of Lab 1 worked with a larger provided dataset of 200 collected points with X,Y coordinates. The RMSE was calculated using Microsoft Excel. A Cumulative Distribution Function was implemented:
")
CDF showing the error distribution of collected point data
Rather than focusing on selected error metrics, the CDF gives a visual indication of the entire error distribution. The graph plots the frequency of observations based upon error. The 68th Percentile here was 3.18, and that matches the location of the CDF plot where the x-axis shows that the amount of error is 68% of the cumulative probability percentage.
References:
Zanbergen. Spatial Data Management: Quality and Control. Fundamentals of Spatial Data Quality. Vancouver Island University, Nanaimo, BC, Canada.
Bolstad, B., & Manson, S. (2022). GIS Fundamentals – 7th Edition. Eider Press.
Leonardo, Alex. (2024, June 10). Cumulative Distribution Function CDF. Statistics HowTo.com https://www.statisticshowto.com/cumulative-distribution-function-cdf/





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}